MIT 6.5840 Lab 3A: Raft - leader election (2025)
前言
今年 Raft lab 的测试新增了一个功能,可以在测试失败时输出下面这样的 HTML 文件,帮助你确认在什么情况下出现了什么问题。
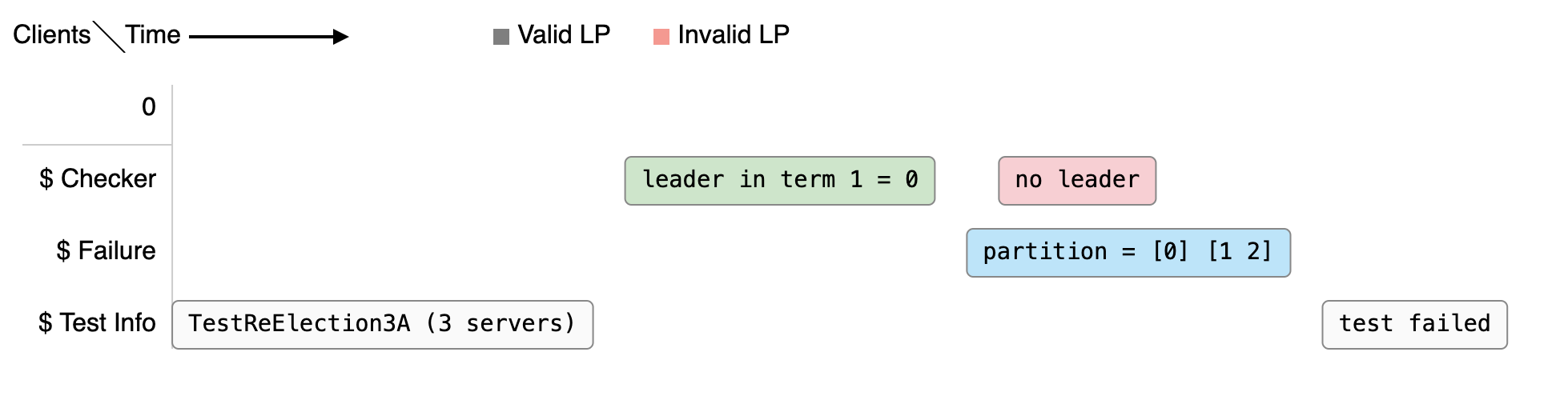
当然,光靠这个并不能帮你 debug 代码中的问题,关于如何实现更好的 debug 工具,请看这篇文章。
题目
Implement Raft leader election and heartbeats (
AppendEntriesRPCs with no log entries). The goal for Part 3A is for a single leader to be elected, for the leader to remain the leader if there are no failures, and for a new leader to take over if the old leader fails or if packets to/from the old leader are lost. Rungo test -run 3Ato test your 3A code.
Lab 3A 只需要实现 leader election,leader 能够在合理的时间内被选出来并且维持 leader 状态,并且在 leader 出问题后新的 leader 能及时被选出。
Election timeout
一个让人头疼的问题是 election timeout 的管理,我们从这里开始讲起。election timeout 有两个含义,分别是 follower 在变为 candidate 并开始 election 前等待的时间,以及 candidate 在开始下一轮 election 前等待的时间。
等待超时与重置计时器
首先要考虑的是什么时候需要等待超时,什么时候需要重置计时器。根据 Figure 2 中的相关内容:
All Servers:
- If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
Followers (§5.2):
- If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate: convert to candidate
Candidates (§5.2):
- On conversion to candidate, start election:
- Reset election timer
- If AppendEntries RPC received from new leader: convert to follower
- If election timeout elapses: start new election
虽然只明确提到了 follower 变为 candidate 并且开始 election 时要重置计时器,但是 follower 在 election timeout 时间内没收到指定的消息(AppendEntries RPC from current leader or granting vote to candidate)会变为 candidate 并开始 election,这意味着收到了这些消息会抑制 follower 变为 candidate,也是需要重置计时器的。另外,所有的 server 只要在 RPC 中碰到了比自己更高的 term,都需要转化为 follower 状态(包括本身就是 follower 的情况),这其中也暗含着需要重置计时器的要求。
根据以上描述,我们可以得出结论:
- follower 超时会变为 candidate 并开始 election;candidate 超时还没成为 leader 并且也没退回成 follower 要发起下一轮 election
- follower 变为 candidate 并且开始 election 时要重置计时器;follower 给 candidate 投票时需要重置计时器;follower 或者 candidate 收到来自 leader 的 AppendEntries RPC 时需要重置计时器;任何 server 在碰到更高的 term 时需要变为 follower 并重置计时器
对 election timeout 的管理会分布在不同的 goroutine 中,需要用锁或者 channel 的方式进行保护。最开始的想法是利用time.Timer类型去实现超时处理和计时器重置,但是 lab 页面不建议使用,所以就没再往这个方向考虑。
Hint: You’ll need to write code that takes actions periodically or after delays in time. The easiest way to do this is to create a goroutine with a loop that calls
time.Sleep(); see theticker()goroutine thatMake()creates for this purpose. Don’t use Go’stime.Timerortime.Ticker, which are difficult to use correctly.
在 lab guidance 页面中有个链接给出了一种解决办法:
The management of the election timeout is a common source of headaches. Perhaps the simplest plan is to maintain a variable in the Raft struct containing the last time at which the peer heard from the leader, and to have the election timeout goroutine periodically check to see whether the time since then is greater than the timeout period. It’s easiest to use
time.Sleep()with a small constant argument to drive the periodic checks. Don’t usetime.Tickerandtime.Timer; they are tricky to use correctly.
在实现完两种方案以后,我发现他们各有千秋。接下来的内容基于上面这个方案,在本文最后,会给出基于time.Timer的实现。
设置超时时间大小
不合理的超时时间会影响系统的可用性。election timeout 如果比 heartbeat 的发送间隔小的话,leader 还没来得及发送 heartbeat 就会收到其他 candidate 的 RequestVote 并变为 follower 状态,这样的系统只会不停重复选举 leader,是完全不可用的;但是 election timeout 又不能太大,否则就不能在 leader 出问题的时候及时选出新的 leader,也会影响系统的可用性。论文 5.6 节给出的公式对于系统的超时时间设置有一定参考价值。 $$ broadcastTime \ll electionTimeout \ll MTBF $$
论文中设置的 election timeout 是 150 到 300 毫秒,这样的设置在 heartbeat 每 10 毫秒进行发送的频率下比较合理。但是 lab 要求每秒最多发十次 heartbeat,所以 election timeout 必须设置得大一些,但也不能太大,要保证能在五秒内选出 leader。
Hint: The paper’s Section 5.2 mentions election timeouts in the range of 150 to 300 milliseconds. Such a range only makes sense if the leader sends heartbeats considerably more often than once per 150 milliseconds (e.g., once per 10 milliseconds). Because the tester limits you tens of heartbeats per second, you will have to use an election timeout larger than the paper’s 150 to 300 milliseconds, but not too large, because then you may fail to elect a leader within five seconds.
因为 election timeout 是随机数,极端情况下不同的 candidate 可能会多次随机到接近的值,导致不停发起新的 election,无法在五秒内选出 leader。把上限设置得低一些可以多支持几轮 election 的机会,把上下限差值设置得大一些可以尽量避免随机到接近的值。
1const (
2 // Because the tester limits you tens of heartbeats per second, you will
3 // have to use an election timeout larger than the paper's 150 to 300
4 // milliseconds, but not too large, because then you may fail to elect
5 // a leader within five seconds.
6 ELECTIONTIMEOUTLEAST = 700 * time.Millisecond
7 ELECTIONTIMEOUTMOST = 1200 * time.Millisecond
8)
为了方便调用,我们定义一个函数,用来生成设定范围的随机时间。
1func getElectionTimeout() time.Duration {
2 return ELECTIONTIMEOUTLEAST + (time.Duration(rand.Int63()) % (ELECTIONTIMEOUTMOST - ELECTIONTIMEOUTLEAST))
3}
计时器实现
在Raft结构体中设置一个表示计时器开始时间的变量。
1type Raft struct {
2 ...
3 startTime time.Time
4 ...
5}
6
7func Make(peers []*labrpc.ClientEnd, me int,
8 persister *tester.Persister, applyCh chan raftapi.ApplyMsg) raftapi.Raft {
9 rf := &Raft{}
10 ...
11 rf.startTime = time.Now()
12 ...
13 return rf
14}
判断超时就是看当前时间和这个变量的差值是否超过了 election timeout。
1electionTimeout := getElectionTimeout()
2rf.mu.Lock()
3shouldBeginElection := time.Since(rf.startTime) > electionTimeout
4rf.mu.Unlock()
重置计时器就是重新把这个变量设置为当前时间。
1rf.mu.Lock()
2rf.startTime = time.Now()
3rf.mu.Unlock()
Server 生命周期
server 启动后默认以 follower 状态运行,直到发生故障前,一直都在 follower、candidate、leader 三种状态之间相互转化,同一时刻只可能处于其中一种状态,整个逻辑可以用ticker方法来表示。
从 follower 状态开始,监测到 election timeout 之后成为 candidate 并开始 election,election 失败就退回 follower(其他 server 成为 leader)或者继续保持 candidate 状态并等待下一次 election(这轮没有 leader);election 成功就成为 leader 并发送 heartbeats 维持 leader 状态,leader 出问题就退回 follower 状态,等待下一次 election。
1func Make(peers []*labrpc.ClientEnd, me int,
2 persister *tester.Persister, applyCh chan raftapi.ApplyMsg) raftapi.Raft {
3 rf := &Raft{}
4 ...
5 rf.state = FOLLOWER
6 ...
7
8 // start ticker goroutine to start elections
9 go rf.ticker()
10
11 return rf
12}
1func (rf *Raft) ticker() {
2 for rf.killed() == false {
3
4 // Your code here (3A)
5 // Check if a leader election should be started.
6 electionTimeout := getElectionTimeout()
7 rf.mu.Lock()
8 shouldBeginElection := time.Since(rf.startTime) > electionTimeout
9 rf.mu.Unlock()
10
11 if shouldBeginElection {
12 isLeader := rf.beginElection()
13 if isLeader {
14 rf.sendHeartbeats()
15 }
16 }
17
18 // pause for a random amount of time between 50 and 350
19 // milliseconds.
20 ms := 50 + (rand.Int63() % 300)
21 time.Sleep(time.Duration(ms) * time.Millisecond)
22 }
23}
需要注意的是这种等待一段时间然后循环检测是否超时的方法,实际的 election timeout 会比设置的时间稍微长一点,不过影响不大。
对于 election 失败以及 leader 出问题的情况的处理分别包含在rf.beginElection()以及rf.sendHeartbeats()这两个方法中。
Raft 数据结构和初始化
接下来我们先定义一下 lab3A 需要用到的字段,方便后面的代码编写。
1const (
2 FOLLOWER = "FOLLOW" // 便于调试,你也可以直接用 iota
3 CANDIDATE = "CANDID"
4 LEADER = "LEADER"
5)
6
7type LogEntry struct {
8 Command interface{}
9 Term int
10}
11
12type Raft struct {
13 ...
14 // Persistent state on all servers
15 currentTerm int // latest term server has seen
16 votedFor int // candidateId that received vote in current term (or -1 if none)
17 log []*LogEntry // log entries
18
19 // Volatile state on all servers
20 state string // the server's state
21 startTime time.Time // the time an election timeout starts
22 cancelElection context.CancelFunc // can be used to cancel the election immediately
23 cancelHeartbeat context.CancelFunc // can be used to cancel the heartbeat immediately
24 ...
25}
26
27func Make(peers []*labrpc.ClientEnd, me int,
28 persister *tester.Persister, applyCh chan raftapi.ApplyMsg) raftapi.Raft {
29 rf := &Raft{}
30 rf.peers = peers
31 rf.persister = persister
32 rf.me = me
33
34 // Your initialization code here (3A, 3B, 3C).
35 rf.votedFor = -1
36 rf.state = FOLLOWER
37 rf.startTime = time.Now()
38
39 // initialize from state persisted before a crash
40 rf.readPersist(persister.ReadRaftState())
41
42 // start ticker goroutine to start elections
43 go rf.ticker()
44
45 return rf
46}
votedFor为-1表示当前 term 还没有投过票。cancelElection和cancelHeartbeat分别用来立即取消 candidate 的 election 以及 leader 的 heartbeat,这可能是因为发现了更高的 term,需要立即变为 follower 状态。
有了上面的定义,GetState方法直接读取相应字段就行。
1// return currentTerm and whether this server
2// believes it is the leader.
3func (rf *Raft) GetState() (int, bool) {
4
5 var term int
6 var isleader bool
7 // Your code here (3A).
8 rf.mu.Lock()
9 defer rf.mu.Unlock()
10
11 term = rf.currentTerm
12 isleader = (rf.state == LEADER)
13
14 return term, isleader
15}
RPC
RequestVote和AppendEntries这两个 RPC 意味着被其他 server 调用的时候需要做的事情,sendRequestVote和sendsendAppendEntries则是调用其他 server 的 RPC。
RequestVote
参数和返回值直接按照 Figure 2 进行设置。
| Arguments | description |
|---|---|
| term | candidate’s term |
| candidateId | candidate requesting vote |
| lastLogIndex | index of candidate’s last log entry (§5.4) |
| lastLogTerm | term of candidate’s last log entry (§5.4) |
| Results | description |
|---|---|
| term | currentTerm, for candidate to update itself |
| voteGranted | true means candidate received vote |
1// example RequestVote RPC arguments structure.
2// field names must start with capital letters!
3type RequestVoteArgs struct {
4 // Your data here (3A, 3B).
5 Term int // candidate's term
6 CandidateId int // the candidate who is requesting vote
7 LastLogIndex int // index of candidate's last log entry
8 LastLogTerm int // term of candidate's last log entry
9}
10
11// example RequestVote RPC reply structure.
12// field names must start with capital letters!
13type RequestVoteReply struct {
14 // Your data here (3A).
15 Term int // the receiver's currentTerm, for candidate to update itself
16 VoteGranted bool // true means candidate received vote
17}
需要注意的是 RPC 要求参数和返回值的结构体成员名都用大写开头。
在RequestVote方法的实现上,Figure 2 写得比较简洁:
Receiver implementation:
- Reply false if term < currentTerm (§5.1)
- If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote (§5.2, §5.4)
- candidate 的 term 比当前收到 RPC 的 server 的 currentTerm 小的时候直接返回 false
- 如果本任期还没有投票或者已经给这个 candidate 投过了票,并且 candidate 的 log 至少和当前 server 一样新的时候,投票给 candidate
第二条中已经给这个 candidate 投过票还继续投的原因是可能投票之后这个 server 就挂掉了,candidate 没有收到 RPC 的返回,然后又重新发起 RPC 调用,这时候 server 又上线了。
实际还有一些细节需要注意,比如收到的 RPC 中的 term 比自己的 currentTerm 大的时候要把 currentTerm 设置为 RPC 中的 term,并且把状态切换为 follower,同时也不要忘了重置计时器。
IF RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
用 early return 的形式,如果当前 term 已经给 candidate 以外的 server 投了票就直接返回。
我们把lastLogIndex和lastLogTerm置为-1表示 log 中还没有 logentry,在比较谁的 log 更新的时候要严格按照论文中的描述:
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
投票完之后还需要重置一下计时器。
在 RPC 返回之前还需要持久化一下状态,目前直接调用给定的persist方法就行。
1// example RequestVote RPC handler.
2func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
3 // Your code here (3A, 3B).
4 rf.mu.Lock()
5 defer rf.mu.Unlock()
6
7 // "If a server receives a request with a stale term number, it rejects the
8 // request."
9 if rf.currentTerm > args.Term {
10 reply.Term = rf.currentTerm
11 reply.VoteGranted = false
12 return
13 }
14
15 // "If one server's current term is smaller than the other's, then it updates
16 // its current term to the larger value. If a candidate or leader discovers
17 // that its term is out of date, it immediately reverts to follower state."
18 if rf.currentTerm < args.Term {
19 rf.currentTerm = args.Term
20 rf.votedFor = -1
21 rf.state = FOLLOWER
22 // reset election timer if you discovers that your term is out of date
23 rf.startTime = time.Now()
24
25 if rf.cancelElection != nil {
26 rf.cancelElection()
27 }
28
29 if rf.cancelHeartbeat != nil {
30 rf.cancelHeartbeat()
31 }
32 }
33
34 // "Each server will vote for at most one candidate in a given term, on a
35 // first-come-first-served basis."
36 if rf.votedFor != -1 && rf.votedFor != args.CandidateId {
37 reply.Term = rf.currentTerm
38 reply.VoteGranted = false
39 return
40 }
41
42 // "The RPC includes information about the candidate's log, and the voter
43 // denies its vote if its own log is more up-to-date than that of the candidate."
44 lastLogIndex := len(rf.log) - 1
45 var lastLogTerm int
46 if lastLogIndex == -1 {
47 lastLogTerm = -1
48 } else {
49 lastLogTerm = rf.log[lastLogIndex].Term
50 }
51 if lastLogTerm > args.LastLogTerm ||
52 (lastLogTerm == args.LastLogTerm && lastLogIndex > args.LastLogIndex) {
53 reply.Term = rf.currentTerm
54 reply.VoteGranted = false
55 return
56 }
57
58 reply.Term = rf.currentTerm
59 reply.VoteGranted = true
60 rf.votedFor = args.CandidateId
61 // reset election timer if you grant a vote to another peer
62 rf.startTime = time.Now()
63
64 // "Updated on stable storage before responding to RPCs."
65 rf.persist()
66}
AppendEntries
因为只用来实现 heartbeats,所以参数和返回值都按最简单的来设置:
1type AppendEntriesArgs struct {
2 Term int // leader's term
3 LeaderId int // so follower can redirect clients
4 PrevLogIndex int // index of log entry immediately preceding new ones
5 PrevLogTerm int // term of PrevLogIndex entry
6}
7
8type AppendEntriesReply struct {
9 Term int // currentTerm, for leader to update itself
10}
AppendEntries方法前面部分基本上跟RequestVote差不多,最后也要重置计时器以及持久化状态。
1func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
2 rf.mu.Lock()
3 defer rf.mu.Unlock()
4
5 // "If a server receives a request with a stale term number, it rejects the
6 // request."
7 if rf.currentTerm > args.Term {
8 reply.Term = rf.currentTerm
9 reply.Success = false
10 return
11 }
12
13 // "If one server's current term is smaller than the other's, then it updates
14 // its current term to the larger value. If a candidate or leader discovers
15 // that its term is out of date, it immediately reverts to follower state."
16 if rf.currentTerm < args.Term {
17 rf.currentTerm = args.Term
18 rf.votedFor = -1
19 rf.state = FOLLOWER
20 // reset election timer if you discovers that your term is out of date
21 rf.startTime = time.Now()
22 }
23
24 reply.Term = rf.currentTerm
25
26 // reset election timer if you get an AppendEntries RPC from the current leader
27 rf.startTime = time.Now()
28
29 if rf.cancelElection != nil {
30 rf.cancelElection()
31 }
32
33 if rf.cancelHeartbeat != nil {
34 rf.cancelHeartbeat()
35 }
36
37 // "Updated on stable storage before responding to RPCs."
38 rf.persist()
39}
调用其他 server 的方法直接模仿sendRequestVote即可:
1func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {
2 ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
3 return ok
4}
选举和心跳
Lab 3A 的实现中最复杂的部分就是ticker中的beginElection和sendHeartbeats方法了,并且这两个方法有一些相似的部分,值得先讨论一下。
在这两个方法中,都需要启动一些 goroutine,并且根据这些 goroutine 的执行结果来进行不同的操作。有时候不用等所有的 goroutine 执行完就可以直接返回(收到了大多数的投票或者心跳得到了大多数的确认);有时候某个 goroutine 的结果就可以导致直接返回(发现了更高的 term);有时候 RPC 执行太慢需要进行超时退出(election timeout 和 heartbeat timeout)。我们需要一种结构来处理所有这些情况。
最明显的特征是主 goroutine 可以通知子 goroutine 退出,反之亦然。我选择用Context来实现这个功能,并且用select来进行超时、提前退出、结果汇总的多路处理,关键代码如下:
1ctx, cancel := context.WithCancel(context.Background())
2countCh := make(chan bool)
3for i := range rf.peers {
4 if i != rf.me {
5 go func(peer int) {
6 ...
7 doneCh := make(chan bool, 1)
8 go func() {
9 ok := rf.sendRPC(peer, &args, &reply)
10 if ok {
11 if reply.xxx {
12 doneCh <- true
13 } else {
14 doneCh <- false
15 }
16 } else {
17 doneCh <- false
18 }
19 }()
20
21 select {
22 case <-ctx.Done():
23 return
24 case result := <-doneCh:
25 countCh <- result
26 return
27 }
28 }(i)
29 }
30}
31
32timeout := time.NewTimer(xxx)
33for {
34 select {
35 case <-timeout.C:
36 return
37 case <-ctx.Done():
38 return
39 case result := <-countCh:
40 ...
41 }
42}
注意代码中使用了一个缓存为 1 的 channel,并且单独开了一个 goroutine 来调用 RPC 并且发送结果到这个 channel。如果不单独开个 goroutine 的话就需要在发送 RPC 结果的同时监控Context,需要在每一个发送结果的地方都进行 select 操作。
1ok := rf.sendRPC(peer, &args, &reply)
2if ok {
3 select {
4 case <-ctx.Done():
5 case countCh <- true:
6 }
7} else {
8 select {
9 case <-ctx.Done():
10 case countCh <- false:
11 }
12}
单独开 goroutine 的方式写法上比较简洁,但是Context被 cancel 之后单独开的 goroutine 可能还需要运行一段时间才会退出,而外层的位于 doneCh 接收侧的 goroutine 可能直接退出了,这就是为什么需要一个 buffered channel 来避免 goroutine leak。
选举
除了上面说到的直接返回的情况,选举过程中还有一种直接返回的情况是收到了 leader 的心跳。
While waiting for votes, a candidate may receive an AppendEntries RPC from another server claiming to be leader. If the leader’s term (included in its RPC) is at least as large as the candidate’s current term, then the candidate recognizes the leader as legitimate and returns to follower state.
要实现这个功能依然可以借助于上面提到的Context实现,不过为了在其他 goroutine 中也能调用 cancel function,我们需要在Raft中额外增加一个字段:
1type Raft struct {
2 ...
3 cancelElection context.CancelFunc // can be used to cancel the election immediately
4}
然后在beginElection中初始化这个字段:
1func (rf *Raft) beginElection() bool {
2 rf.mu.Lock()
3 ...
4 ctx, cancel := context.WithCancel(context.Background())
5 defer cancel()
6 rf.cancelElection = cancel
7 ...
8 rf.mu.Unlock()
9 ...
10}
在收到心跳之后就可以调用rf.cancelElection()来取消正在进行的 election:
1if rf.cancelElection != nil {
2 rf.cancelElection()
3}
完整代码如下:
1func (rf *Raft) beginElection() bool {
2 rf.mu.Lock()
3 rf.state = CANDIDATE
4 rf.currentTerm++
5 rf.votedFor = rf.me
6 rf.startTime = time.Now() // reset election timer
7 ctx, cancel := context.WithCancel(context.Background())
8 defer cancel()
9 rf.cancelElection = cancel
10 lastLogIndex := len(rf.log) - 1
11 var lastLogTerm int
12 if lastLogIndex == -1 {
13 lastLogTerm = -1
14 } else {
15 lastLogTerm = rf.log[lastLogIndex].Term
16 }
17 currentTerm := rf.currentTerm
18 rf.mu.Unlock()
19
20 ticket := 1
21 count := 0
22 voteCh := make(chan bool)
23
24 for i := range rf.peers {
25 if i != rf.me {
26 go func(peer int) {
27 args := RequestVoteArgs{
28 Term: currentTerm,
29 CandidateId: rf.me,
30 LastLogIndex: lastLogIndex,
31 LastLogTerm: lastLogTerm,
32 }
33 var reply RequestVoteReply
34
35 doneCh := make(chan bool, 1) // use buffered channel to avoid goroutine leak
36 go func() {
37 ok := rf.sendRequestVote(peer, &args, &reply)
38 if ok {
39 if reply.Term > args.Term {
40 rf.mu.Lock()
41 rf.currentTerm = reply.Term
42 rf.mu.Unlock()
43 cancel()
44 return
45 }
46 if reply.VoteGranted {
47 doneCh <- true
48 } else {
49 doneCh <- false
50 }
51 } else {
52 doneCh <- false
53 }
54 }()
55
56 select {
57 case <-ctx.Done():
58 return
59 case result := <-doneCh:
60 voteCh <- result
61 return
62 }
63 }(i)
64 }
65 }
66
67 electionTimeout := getElectionTimeout()
68
69 for {
70 select {
71 case <-ctx.Done():
72 rf.mu.Lock()
73 rf.state = FOLLOWER
74 rf.mu.Unlock()
75 return false // find a larger term or receive heartbeats from leader
76 case vote := <-voteCh:
77 count++
78 if vote {
79 ticket++
80 }
81 if ticket > len(rf.peers)/2 {
82 rf.mu.Lock()
83 rf.state = LEADER
84 rf.mu.Unlock()
85 return true // win the election
86 }
87 if count == len(rf.peers)-1 {
88 return false // lose the election
89 }
90 default:
91 rf.mu.Lock()
92 shouldBeginAnotherElection := time.Since(rf.startTime) > electionTimeout
93 rf.mu.Unlock()
94 if shouldBeginAnotherElection {
95 return false // use `return rf.beginElection()` instead?
96 }
97 }
98 }
99}
多种情况调用同一个Context简化了代码,但同时也让调试变得困难了,因为不确定case <-ctx.Done()的时候到底是发现了更大的 term 还是收到了 leader 的心跳。如果对这个方面有要求,可以考虑取消共用Context,发现更大的 term 之后用一个专门的 channel 通知主 goroutine。
关于检测超时的部分,因为是判断时间差值的办法,所以逻辑需要放在default里面,如果用的time.Timer方法这边会简单一些。
另外,检测到超时之后要开始下一轮 election,这边直接返回 false 后控制权回到 ticker方法,短暂睡眠一段时间之后开启下一轮 election,但是感觉用递归才是更直观的选择?
The third possible outcome is that a candidate neither wins nor loses the election: if many followers become candidates at the same time, votes could be split so that no candidate obtains a majority. When this happens, each candidate will time out and start a new election by incrementing its term and initiating another round of RequestVote RPCs.
心跳
heartbeat timeout
很容易忽略的一件事是心跳也有超时,因为 RPC 从调用到返回可能花费较长时间,这个时间可能会超过 election timeout,如果 leader 一直等待 RPC 返回,那么可能其他 server 已经开始 election 甚至选出了新的 leader,这个 leader 还在等待。所以心跳的超时时间一定要小于 election timeout,但是要比前面提到的 broadcastTime 尽量大一些,否则选出来的 leader 会频繁超时退回到 follower 状态。在 RPC 调用正常的情况下,我们每隔一定的时间重复一次,为了满足每秒最多十次心跳的要求,这个时间不能少于 100 毫秒(实际可以稍微小于 100,因为最快的 RPC 调用也需要一些时间)。
1const (
2 // Heartbeat RPCs should finish within this time. Cannot be too small,
3 // beacuse the leader will convert to follower state easily. Cannot be
4 // too large, because the leader may not convert to follower just in time
5 // when there's a network partition and the leader become disconnected
6 // from the other servers.
7 HEARTBEATTIMEOUT = 500 * time.Millisecond
8 // The tester requires that the leader send heartbeat RPCs no more than
9 // ten times per second.
10 HEARTBEATINTERVAL = 100 * time.Millisecond
11)
心跳只要失败返回都需要变为 follower 状态,我们用一个defer来实现。
在主要结构方面跟上面最大的区别是外面套了一层for循环,因为正常情况下心跳是一个不断重复的过程。另外一个区别是检测超时的部分用time.Timer来实现。
在最后,因为有select的存在我们需要设置 label 才能跳出select外层的for循环。
1func (rf *Raft) sendHeartbeats() {
2 defer func() {
3 rf.mu.Lock()
4 rf.state = FOLLOWER
5 rf.mu.Unlock()
6 }()
7
8 rf.mu.Lock()
9 currentTerm := rf.currentTerm
10 rf.mu.Unlock()
11
12 for {
13 countCh := make(chan bool)
14 ctx, cancel := context.WithCancel(context.Background())
15 defer cancel()
16
17 for i := range rf.peers {
18 if i != rf.me {
19 go func(peer int) {
20 args := AppendEntriesArgs{
21 Term: currentTerm,
22 LeaderId: rf.me,
23 }
24 var reply AppendEntriesReply
25
26 doneCh := make(chan bool, 1)
27 go func() {
28 // this may spend a lot of time to finish
29 ok := rf.sendAppendEntries(peer, &args, &reply)
30 if ok {
31 if args.Term < reply.Term {
32 rf.mu.Lock()
33 rf.currentTerm = reply.Term
34 rf.mu.Unlock()
35 cancel()
36 } else {
37 doneCh <- true
38 }
39 } else {
40 countCh <- false
41 }
42 }()
43
44 select {
45 case <-ctx.Done():
46 return
47 case result := <-doneCh:
48 countCh <- result
49 }
50 }(i)
51 }
52 }
53
54 success := 0
55 count := 0
56 // each round of heartbeat should finish within this amount of time
57 timeout := time.NewTimer(HEARTBEATTIMEOUT)
58 defer timeout.Stop()
59 OuterLoop:
60 for {
61 select {
62 case <-timeout.C:
63 return
64 case <-ctx.Done():
65 return
66 case result := <-countCh:
67 count++
68 if result {
69 success++
70 }
71 if count == len(rf.peers)-1 {
72 if success < len(rf.peers)/2 {
73 return
74 } else {
75 break OuterLoop
76 }
77 }
78 }
79 }
80 time.Sleep(HEARTBEATINTERVAL)
81 }
82}
后记
使用time.Timer的代码结构类似这样:
1const (
2 ELECTIONTIMEOUTLEAST = 500 * time.Millisecond
3 ELECTIONTIMEOUTMOST = 1000 * time.Millisecond
4)
5
6type Raft struct {
7 ...
8 electionTimeout *time.Timer
9}
10
11func getElectionTimeout() time.Duration {
12 return ELECTIONTIMEOUTLEAST + (time.Duration(rand.Int63()) % ELECTIONTIMEOUTMOST)
13}
14
15func Make(peers []*labrpc.ClientEnd, me int,
16 persister *tester.Persister, applyCh chan raftapi.ApplyMsg) raftapi.Raft {
17 rf := &Raft{}
18 ...
19 rf.electionTimeout = time.NewTimer(getElectionTimeout())
20 ...
21 go rf.ticker()
22 return rf
23}
24
25func (rf *Raft) ticker() {
26 for rf.killed() == false {
27 <-rf.electionTimeout.C
28 isLeader := rf.beginElection()
29 if isLeader {
30 rf.sendHeartbeats()
31 }
32 }
33}
34
35func (rf *Raft) resetElectionTimeout() {
36 rf.electionTimeout.Reset(getElectionTimeout())
37}
38
39func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
40 ...
41 rf.resetElectionTimeout()
42 ...
43}
44
45func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
46 ...
47 rf.resetElectionTimeout()
48 ...
49}
50
51func (rf *Raft) beginElection() bool {
52 ...
53 rf.resetElectionTimeout()
54 ...
55 select {
56 case <-rf.electionTimeout.C:
57 rf.electionTimeout.Reset(0) // 这边很重要,否则会导致 ticker 中 <-rf.electionTimeout.C 阻塞
58 return false
59 ...
60 }
61}